INTRODUCTION
Artificial Intelligence (AI) chatbots have become increasingly popular tools for patients seeking health information. The ability of AI chatbots to offer accurate, understandable, and reliable information for common conditions can bridge gaps in healthcare information access.1-3 This study explores how well 4 chatbots, OpenAI ChatGPT 4o mini, Microsoft Copilot, Google Gemini (Flash 1.5), and Perplexity AI (Version 2.33.3), perform in providing guidance on common dermatologic conditions and comparing them to American Academy of Dermatology (AAD) patient resources.4
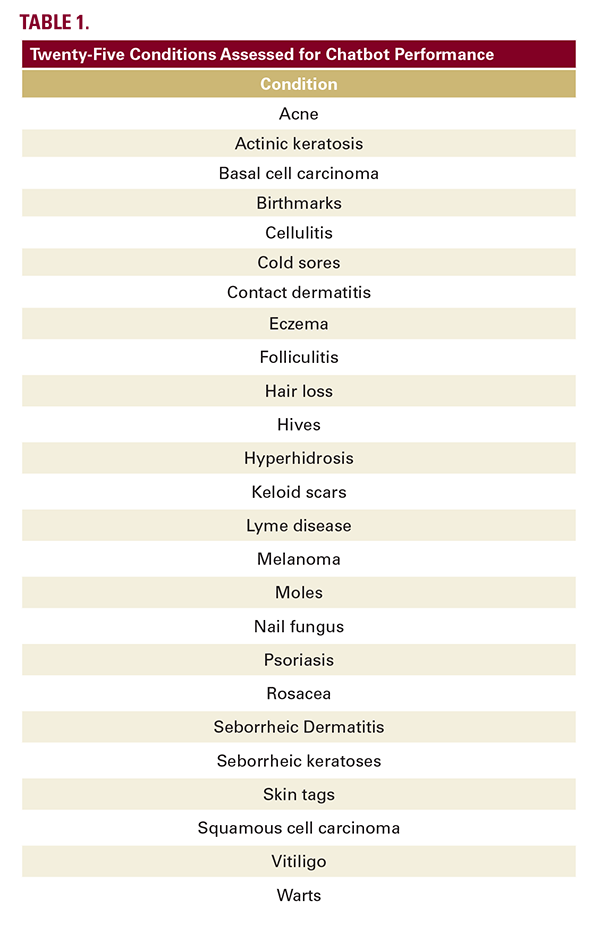
A prompt, "tell me about (condition)," was entered into 4 chatbots for 25 dermatologic conditions (Table 1), which were assessed for readability, accuracy, and quality. In addition, 280 articles from the AAD website that discussed these 25 conditions were also assessed. The DISCERN tool evaluated quality while the Patient Education Materials Assessment Tool (PEMAT) judged understandability and actionability. The Canadian Press’s 1-5 scale was employed to rate misinformation. Intraclass Correlation (DISCERN, Misinformation) and Cohen's Kappa (PEMAT) assessed inter-rater reliability, with ANOVA comparing significance.
There was moderate, good, and high level of agreement between raters for Misinformation, DISCERN, and PEMAT, respectively. The quality of responses was moderate for all, with Copilot and Perplexity scoring highest and Gemini lowest. Chatbots generally lacked comparative details regarding potential treatments, leading to lower scores. Understandability and actionability were relatively high, with ChatGPT performing best. All chatbot responses were accurate. ChatGPT offered the most thorough information, whereas Gemini's responses required confirmatory information, warranting a lower score (Table 2). Copilot and Perplexity provided consistent sources within responses, while Gemini was variable in sourcing, and ChatGPT lacked sources.
Chatbot responses were at a 10th-grade reading level; however, as 54% of adults in the US read below a 6th-grade level, chatbot responses may be poorly understood.5 ChatGPT, in particular, was more verbose than the other chatbots. While this can explain its comprehensiveness and accuracy, it might also overwhelm or distract users from crucial information. While chatbots could customize responses by reading level, it is unlikely patients would specifically prompt this.2 Compared to the four chatbots, the AAD website's materials were more readable and specifically tailored, though chatbot responses were more concise and consistent in word count.
A prompt, "tell me about (condition)," was entered into 4 chatbots for 25 dermatologic conditions (Table 1), which were assessed for readability, accuracy, and quality. In addition, 280 articles from the AAD website that discussed these 25 conditions were also assessed. The DISCERN tool evaluated quality while the Patient Education Materials Assessment Tool (PEMAT) judged understandability and actionability. The Canadian Press’s 1-5 scale was employed to rate misinformation. Intraclass Correlation (DISCERN, Misinformation) and Cohen's Kappa (PEMAT) assessed inter-rater reliability, with ANOVA comparing significance.
There was moderate, good, and high level of agreement between raters for Misinformation, DISCERN, and PEMAT, respectively. The quality of responses was moderate for all, with Copilot and Perplexity scoring highest and Gemini lowest. Chatbots generally lacked comparative details regarding potential treatments, leading to lower scores. Understandability and actionability were relatively high, with ChatGPT performing best. All chatbot responses were accurate. ChatGPT offered the most thorough information, whereas Gemini's responses required confirmatory information, warranting a lower score (Table 2). Copilot and Perplexity provided consistent sources within responses, while Gemini was variable in sourcing, and ChatGPT lacked sources.
Chatbot responses were at a 10th-grade reading level; however, as 54% of adults in the US read below a 6th-grade level, chatbot responses may be poorly understood.5 ChatGPT, in particular, was more verbose than the other chatbots. While this can explain its comprehensiveness and accuracy, it might also overwhelm or distract users from crucial information. While chatbots could customize responses by reading level, it is unlikely patients would specifically prompt this.2 Compared to the four chatbots, the AAD website's materials were more readable and specifically tailored, though chatbot responses were more concise and consistent in word count.